Start here
Scribe tries to extract as much information about your API as it can from your code, but you can (and should) help it by providing more information.
By default (and in the examples here), Scribe extracts info from your controller/request handler. However, if you prefer an alternative approach, the third-party plugin Scribe-TDD allows Scribe to extract the documentation from your API tests instead.
For example, let's take a simple "healthcheck" endpoint:
Route::get('/healthcheck', function () {
return [
'status' => 'up',
'services' => [
'database' => 'up',
'redis' => 'up',
],
];
});
From this, Scribe gets:
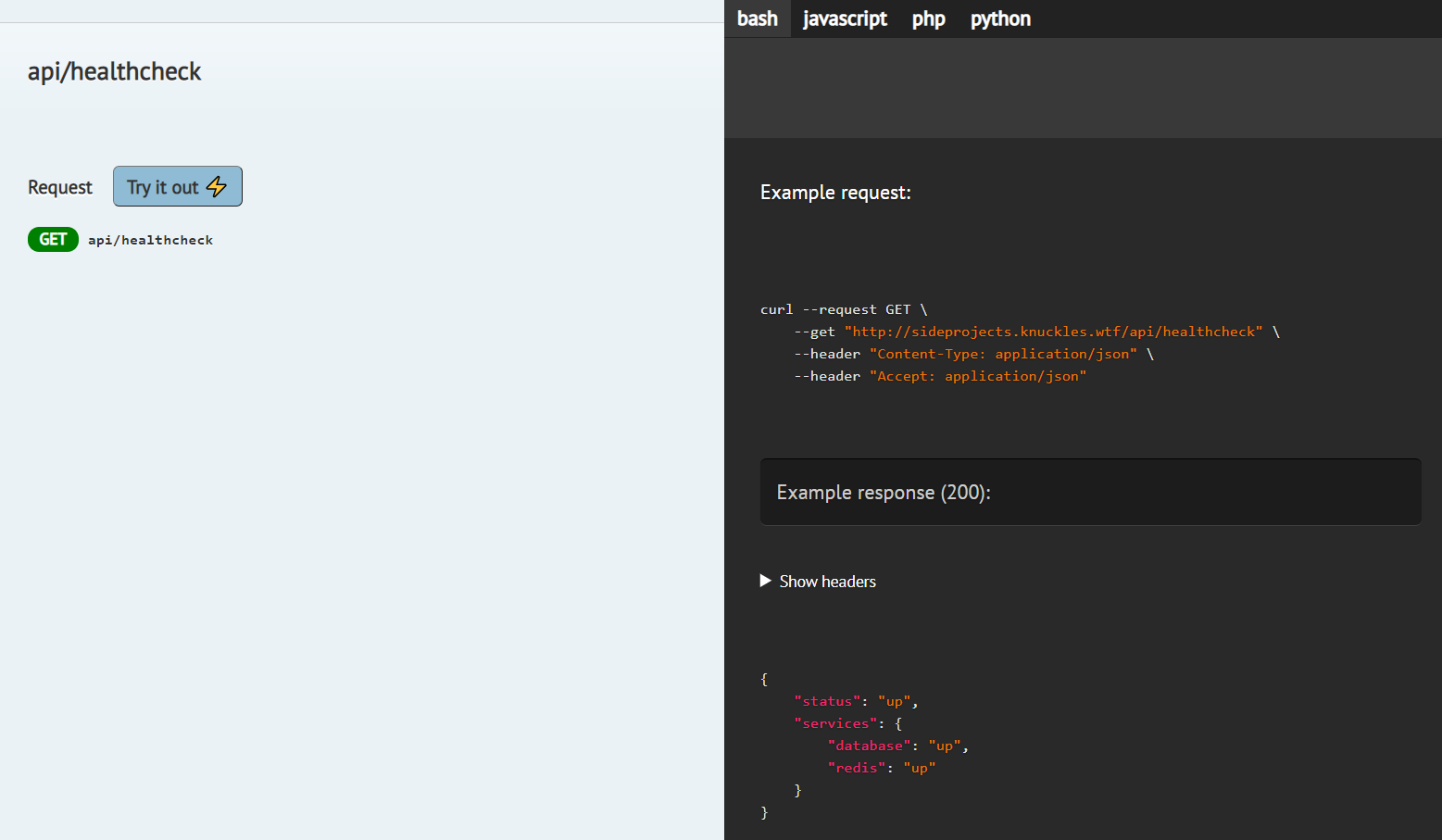
It's not much, but it's a good start. We've got a URL, example requests, and an example response. Plus, an API tester (Try It Out).
We can make this better by adding some annotations:
/**
* Healthcheck
*
* Check that the service is up. If everything is okay, you'll get a 200 OK response.
*
* Otherwise, the request will fail with a 400 error, and a response listing the failed services.
*
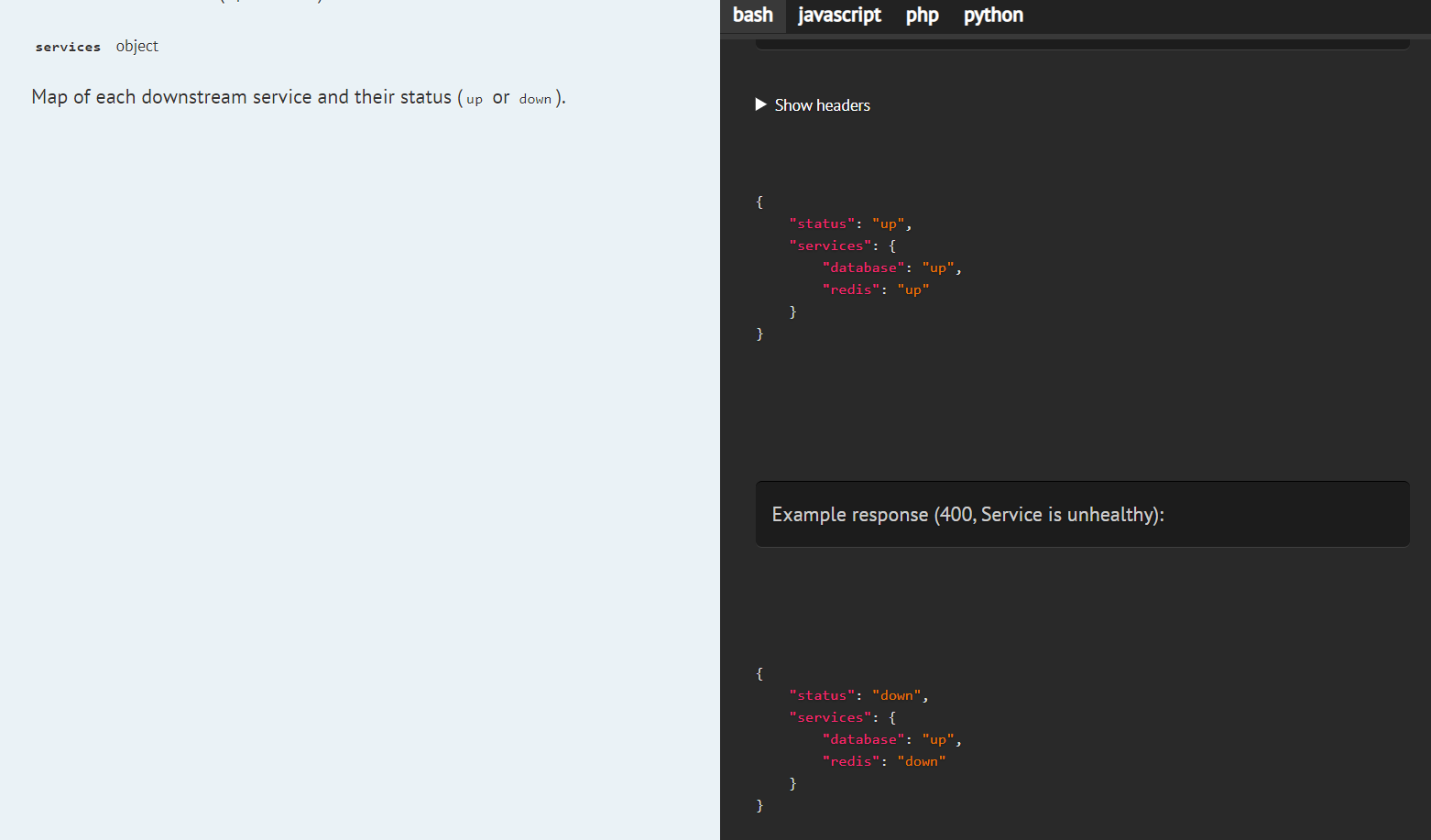
* @response 400 scenario="Service is unhealthy" {"status": "down", "services": {"database": "up", "redis": "down"}}
* @responseField status The status of this API (`up` or `down`).
* @responseField services Map of each downstream service and their status (`up` or `down`).
*/
Route::get('/healthcheck', function () {
return [
'status' => 'up',
'services' => [
'database' => 'up',
'redis' => 'up',
],
];
});
We've added a title and description of the endpoint (first three lines). We've also added another example response, plus descriptions of some of the fields in the response.
Now, we get richer information:
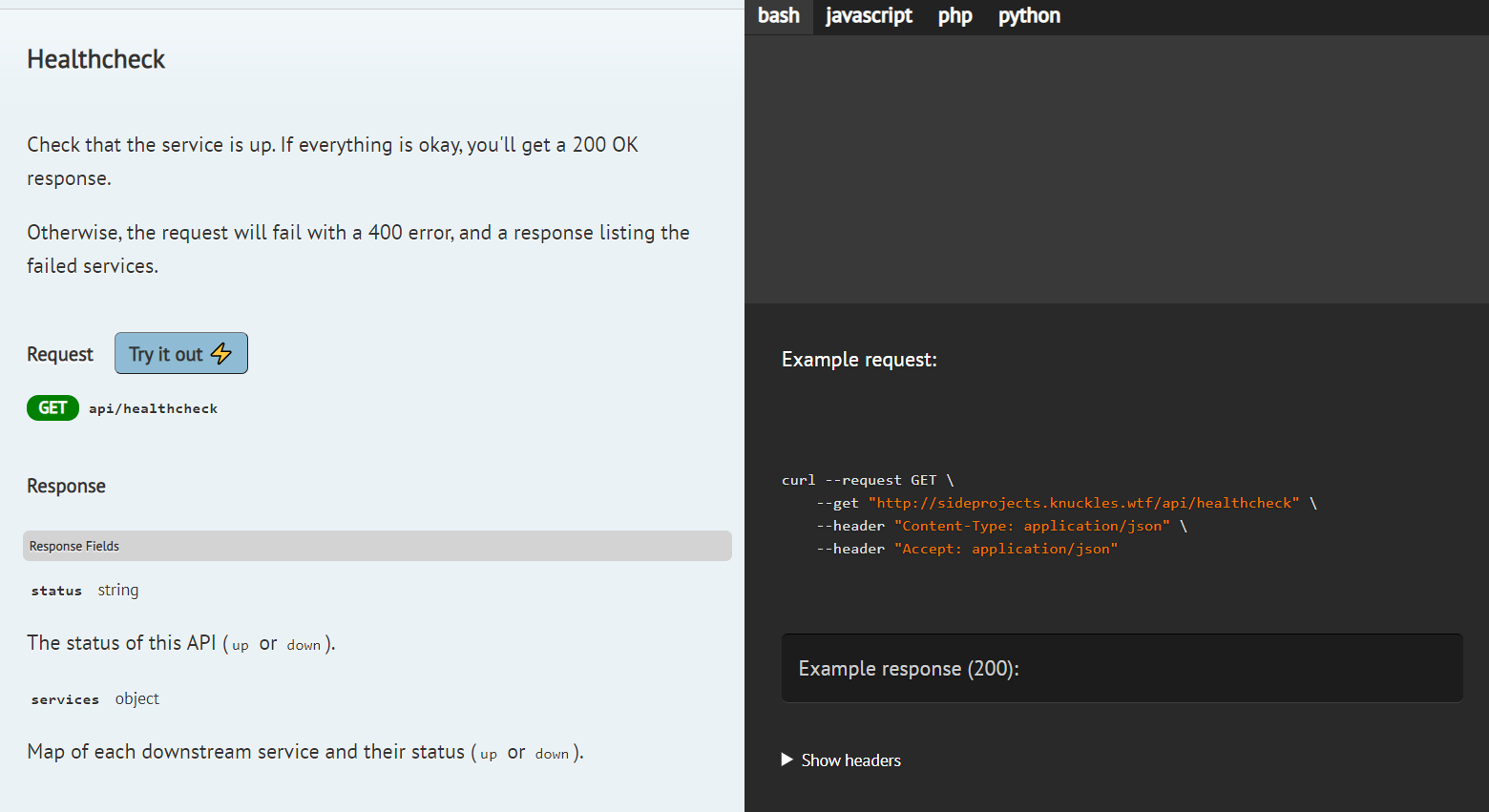
Sure, our method is a bit noisier now, but that's not all bad! In fact, it has a big advantage—the docs are next to the code, so:
- it's harder to forget to update them when you change the code
- a new dev can instantly see the docs and understand the endpoint's behaviour.
Of course, Scribe tries to ensure annotations use a human-readable syntax, so they make sense to you, not just to the machine.
Apart from these annotations, Scribe supports some other ways to annotate your API. For example, you can provide general API information and defaults in your config/scribe.php, add or edit YAML files containing the endpoint details (more on that here), or use custom strategies that read your code.
We'll demonstrate these in the next few sections.
You can exclude an endpoint from the documentation by using the @hideFromAPIDocumentation tag in its docblock.