Scribe for Laravel v3 is here
Scribe v3 is here, with a bunch of new features. There were three main goals with this release:
- Support real-world doc generation workflows better
- Figure out more API and endpoint details automatically
- Make it easier to customise
Here are the key changes we've made in v3 to get closer to these goals. See the migration guide for details on how to upgrade.
Matching your workflow
We realized that Scribe wasn't very flexible beyond a local environment. Which sucks, because when working with other devs, you don't want to depend on each dev to generate docs locally. Some things we've changed:
static fixes��
static-type docs now work properly. Previously, the CSS failed to load if your Laravel app was running (which was silly, and meant you had to specifically configure Nginx or .htaccess in production).
Now you can access them by visiting /docs when your Laravel app is running, or by opening the index.html file directly when your app isn't running.
Multiple URLs
Scribe now lets you configure three main URLs:
- the base URL, which is displayed in the docs (config:
base_url) - the Try It Out URL, which is where Try It Out requests will be sent (config:
try_it_out.base_url), and - the response calls URL, which is the URL set as the current domain for response calls. This is always set to your app's current URL (
config('app.url'))
This means you can fetch sample responses from your local app, have your docs display your production domain, and have Try It Out requests go to your staging domain—or whatever works for you. You can leave any ones you don't need as null, and Scribe will use config('app.url').
More reliable
You might have faced issues in the past with generating your docs in CI or as part of your deployment. A common issue was getting warnings of "Skipping modified file", and having to use --force (which overwrites any manual changes). Scribe v3 fixes this by using a different system to track user modifications. Now you can run generate on different machines without problems.
Smarter and more detailed
We've also tried to get Scribe to extract more details out-of-the-box, as well as be more accurate with those details.
Inline validators + more validation rules
This is probably the biggest news of this release: _inline validators are now supported_🎉🎉. This means Scribe can now extract parameters from your $request->validate() and Validator::make() calls in your controller:
public function createPost($request)
{
$validated = $request->validate([
// Contents of the post
'content' => 'string|required|min:100',
// The title of the post. Example: My First Post
'title' => 'string|required|max:400',
'author_display_name' => 'string',
'author_homepage' => 'url',
'author_timezone' => 'timezone',
'author_email' => 'email|required',
// Date to be used as the publication date.
'publication_date' => 'date_format:Y-m-d',
// Category the post belongs to.
'category' => ['in:news,opinion,quiz', 'required'],
]);
return Post::create($validated);
}
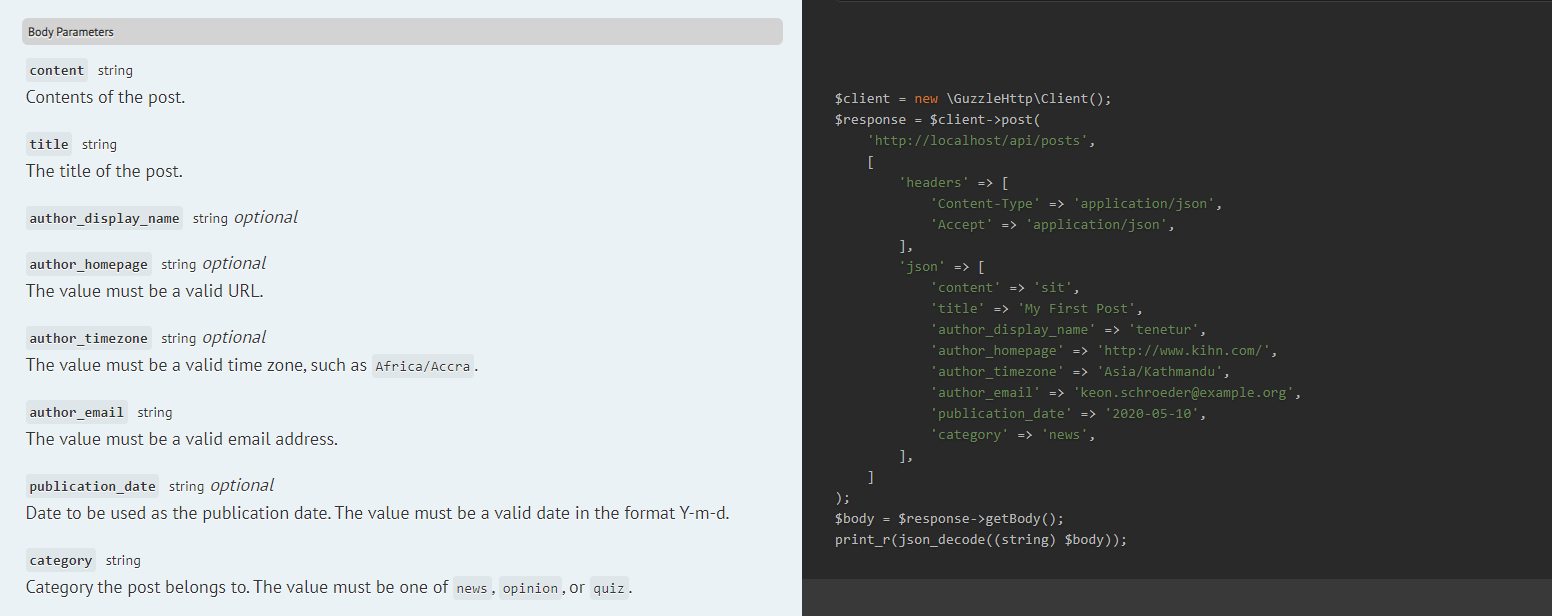
Right from the early days, this has been a popular request, and now it's here. It's experimental, so there are a few limitations on what is supported, but we think it will prove really useful to a lot of folks.
We've also added support for several more validation rules. Some offer "full support" (meaning Scribe will generate an example that passes), while some only have partial support (only used to create a description).
Head over to the docs to learn more, and if you find something that's not right, open an issue or send in a PR.
Smarter URL parameters
Scribe is now better at inferring details about URL parameters. For instance:
- For resource routes like
/users/{user}, it correctly shows the path as/users/{id}. - For ID parameters like
/users/{id}/posts/{post_id}or/users/{user}/posts/{post}, Scribe will guess the two parameters'- names (
idandpost_id), - types (type of your
UserandPostmodel primary keys), and - descriptions ("The ID of the user", and "The ID of the post").
- names (
Of course, you can still override these with @urlParam.
Shout out to GitHub users @kw-pr and @carestad for suggesting these changes.
Response headers
Previously, you could only have the status code, content and description for a response. In v3, you can now have headers too.
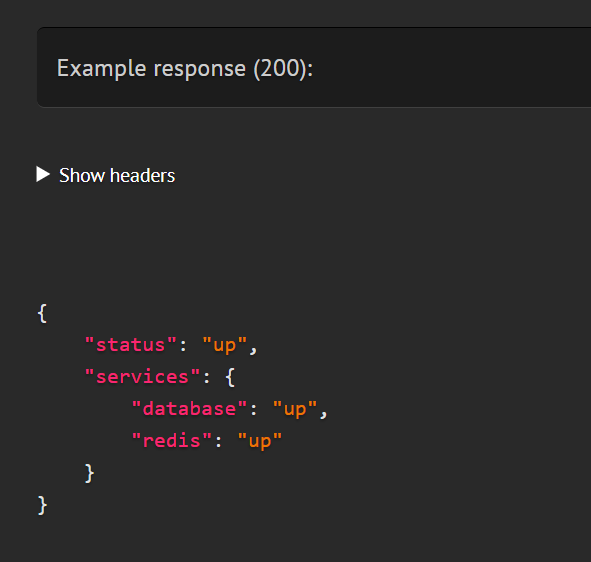
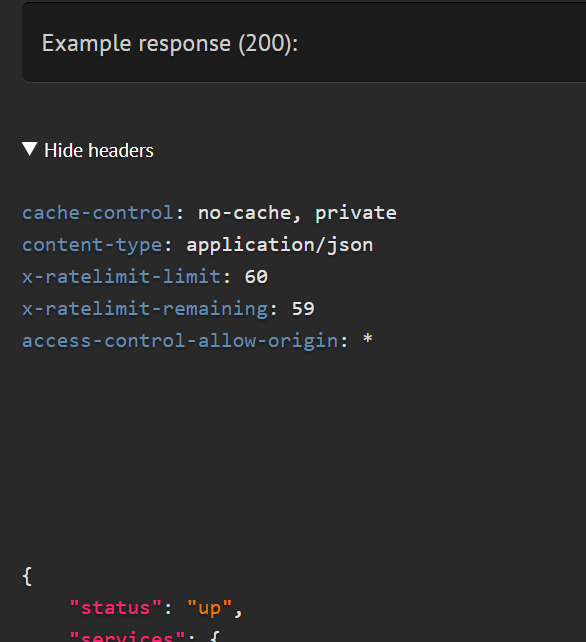
Currently, this only happens for response calls, but we'll enable this in other strategies down the road. In the meantime, if you have any custom response strategies, you can update them to return headers too.
return [
[
"status" => 200,
"description" => 'Success',
"headers" => [
"x-ratelimit-remaining" => [ 99 ],
],
"content" => "{}"
],
];
Easier to customize
While we're trying to make Scribe smarter, we know that it won't always get things right. It's important that humans can override the machine when it's wrong.
Structured output
Scribe has always had the concept of "intermediate" output—a place where it writes the data it has been able to extract about your API, giving you a chance to overwrite some things before they were converted to HTML.
In the past, this was a set of Markdown files, with one group of endpoints per file. You could edit a file, but this effectively froze the file—Scribe would no longer update that file. This meant that you either allowed Scribe keep the incorrect info, or change it yourself, but forfeit any future updates to that group of endpoints.
With v3, we've gone with a better approach (codenamed Camel). Scribe now uses YAML files for intermediate output (endpoint details only; "Introduction" and "Authentication" sections are still Markdown). This means you can change a specific section in a file, and Scribe will respect that section, while still continuing to update other sections within the same file on future runs.
For example, a Camel file containing a group of endpoints might look like this:
name: 'Name of the group'
description: A description for the group.
endpoints:
- httpMethods: ["POST"]
uri: api/stuff
metadata:
title: Do stuff
description:
authenticated: false
headers:
Content-Type: application/json
urlParameters: []
queryParameters: []
bodyParameters:
a_param:
name: a_param
description: Something something
required: true
example: something
type: string
responses:
- status: 200
content: '{"hey": "there"}'
headers: []
description: '200, Success'
responseFields: []
- # Another endpoint...
You could then change the type of a_param to integer. On future runs, Scribe will respect your changes and leave the urlParameters section of that endpoint unchanged, while updating other sections and endpoints in the same file.
Even better, if you don't like how the endpoints or groups are sorted, you can change it. Reorder the items in the endpoints key or rename the group files as you wish, and Scribe will sort your groups and endpoints accordingly. You can even add custom endpoints that aren't actually in your codebase. Awesome, right?
For more details, check out modifying the docs after generating.
Theming
Another big request over the years—Scribe now makes it easier to customise the UI of your docs. When you migrate, you'll notice a new theme item in your config file.
It's still early days. For now, there's only the default theme. But we've laid the foundation that enables us to ship more themes in the future, and we've defined a clear path for you to add/customise yours. Check out the theming guide.
Endpoint objects
We've reworked the plugin API and most of the templates so that the endpoint detailsareis now a value object, not just an array with arbitrary keys. This way, you can avoid typos and get code completion and typechecking in your IDE when writing custom strategies or templates.
// Before:
$route['uri']; // Easy to make a typo
// After:
@php
/** @var \Knuckles\Camel\Output\OutputEndpointData $endpoint */
@endphp
$endpoint->uri; // Now our IDE can auto-suggest valid properties
There's still a lot of work to do—more improvements we had planned that didn't make it into v3. But, in the meantime, we hope these changes make using Scribe a more pleasant experience for you. If something's not right, please open an issue. And if you'd like to support my work, consider getting my course on writing kickass API documentation.
Now, go migrate!